




God I'm tired. If I hear one more "SEO is dead, AEO is the future", I'm going to lose my mind. I want you to know, going in, I'm only going to tell you the things that have moved the needle for us. Not some elaborate ruse to sell you a course. But before we start...
What should we call it
The acronyms keep multiplying, but they all describe one job: getting cited when an AI answers a question.
- Answer engine optimization (AEO) is the practice of structuring content so AI answer engines like ChatGPT, Claude, and Perplexity pick it as a cited source. The term grew out of the SEO industry and shows up most in developer circles.
- Generative engine optimization (GEO) is the same discipline under a different name: shaping content to be surfaced and quoted inside AI-generated answers. The label comes from a 2023 academic paper and got adopted by marketing teams. If your client reads marketing blogs, they'll say GEO.
- LLM SEO (and its synonyms AI SEO, LLMO) is the broad umbrella term for ranking in and getting quoted by large language models. Whichever one your team says, the work underneath is identical.
Dom Sipowicz, a forward deployed engineer at Vercel, has been keeping score since 2025:
The number one task for the AI SEO industry should be to agree on one name! Currently we have: * AI SEO * AEO * GEO * AIO * LLM * SEO * LLMO * LEO LMAO?
That being said, I do like his definitions here, and I'll be using these from here on out.
Alternative dictionary: LLM SEO - simply LLM SEO AEO = AI Engine Optimisation LLMO - LLM Optimisation LLEO = LLM Engine Optimisation LEO - LLM Engine Optimisation GEO - GenerativeAI Engine Optimisation
You'll notice, even he finds it difficult to standardise = and -, so god knows how we'll handle these acronyms.
The tactics underneath are identical. Structured content, accurate metadata, clean markup, content agents can quote. If a consultant tells you GEO needs a fundamentally different strategy from AEO, they're selling you the same audit twice. We run a generative engine optimisation service and it's definitely not to capitalise on an emerging keyword.
Anyway, I digress.
What's actually new
Agents are a new class of visitor. They:
- Sometimes can't run JavaScript reliably
- Choke on ads, navigation, footers, and cookie banners
- Have small context windows, so wasted tokens cost real money
- Prefer structured text they can quote verbatim
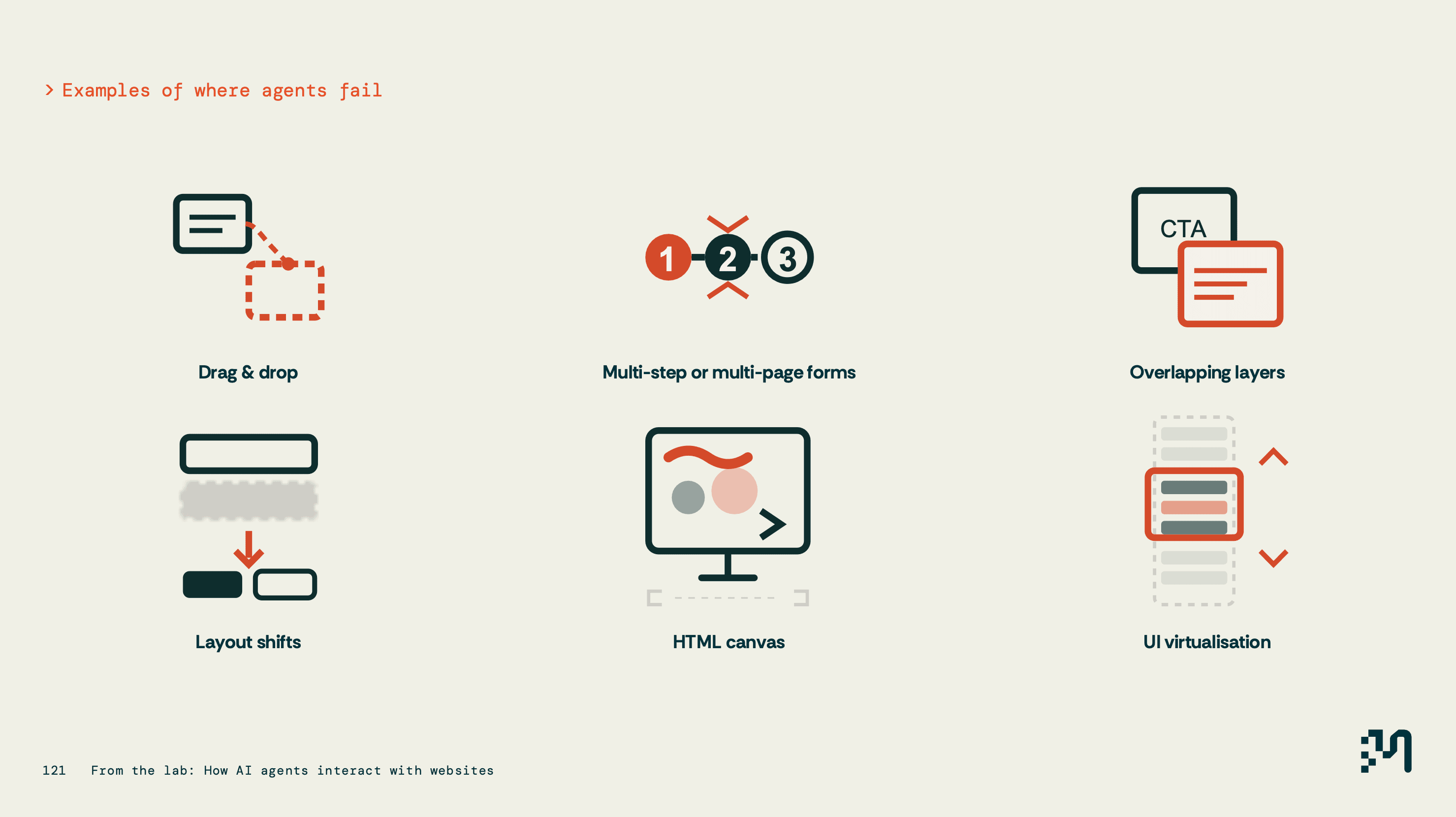
It's the best one-screen summary of the problem I've seen. Merj's lab testing found agents fail on exactly the patterns modern frontends love: drag and drop, multi-step forms, overlapping layers, layout shifts, canvas rendering, and UI virtualisation. In every case the content exists, the agent just can't reach it. If your pricing lives in a canvas-rendered table or your nav is virtualised, you're invisible to agents no matter how good the words are.
One thing we've observed though: they absolutely love markdown if they accept it. So much so that we had a 10k uptick of visitors from GPTBot in the space of 5 mins. I'm not joking. Hold that thought, because what a spike like that does to your bill gets its own section further down.
The SEO half (nothing changed)
Before any AEO plumbing, do the SEO that's been working since the Panda update. Quick summary, since you've probably read this before:
- Titles target the actual query, sentence case, under 60 characters
- Meta descriptions are written for humans and include the keyword
- Schema markup where it earns rich results:
BlogPosting,FAQPage,Service - Internal links from blog posts to relevant service pages (like this one), not just topic clusters
- Real backlinks from people who chose to cite you, not directories
- Content that says something specific, not "the ultimate guide to [topic]"
Three observations from doing this for a few years:
- Your title tag is the single biggest lever. Position 8 with a 0.2% click-through is a title problem, however good the content underneath it is. Fix titles before you write a word of new content.
- Internal linking is undervalued and free. We added contextual CTAs from every blog post to the most relevant service page. Took an afternoon. The blog cluster now feeds traffic into services rather than dead-ending at "related posts".
- Most "AEO checklists" are SEO checklists with the word "answer" added. If you skip the SEO basics, no amount of
llms.txtwill save you.
The Next.js implementation of the boring half
Three patterns cover most of it on an App Router site.
Metadata with fallbacks, not requirements. Every page derives its meta from the data layer, with optional overrides that fall back:
JSON-LD derived at render time, never hand-authored. The most common mistake we see is structured data as a separate editing surface. It drifts within a sprint. Generate it from fields you already have:
One helper function, rendered in a <script type="application/ld+json"> tag. Answer engines weight structured data heavily when picking citation sources. Show both dates visibly on the page too: between two posts answering the same question, the one updated last month usually wins the citation.
A sitemap where lastmod is real. Google has said publicly that it largely ignores priority and changefreq. The freshness signal is lastModified, so generate it from the same data that powers the pages:
Every JSON-LD type worth shipping (and a prompt that builds them)
The BlogPosting example above is one of seven. Here's the full set we wire up, where each one lives, and what feeds it:
| Schema | Where | Feeds on |
|---|---|---|
Organization | Root layout, once | Company name, logo, social profiles |
WebSite | Root layout, once | Site name and URL |
Person | Author bylines and author pages | Name, role, photo, socials |
BlogPosting | Every post | Title, description, both dates, author, image |
BreadcrumbList | Every nested page | Derived from the URL structure |
FAQPage | Pages with real FAQs | Your existing FAQ content |
Service or Product | Offering pages | Name, description, provider |
The one people skip is the most important: Organization.sameAs with your social links is how engines connect your X, LinkedIn and GitHub presence to your domain. That entity graph is what gets a brand cited by name instead of as "one source".
Don't fill any of this in by hand. Paste this into Claude Code, Cursor, or whatever agent lives in your repo, and answer its questions:
Ten minutes of answering questions and the whole entity graph is done, derived from your real data, with nothing for editors to maintain. Spot-check the output in the Rich Results Test before you ship.
The new half (content negotiation)
Now the actually new bit. Here's what each piece does on robotostudio.com.
The Accept header tells you who's asking
The HTTP Accept header is how a client tells the server which formats it can handle. Browsers send text/html. Agents that want markdown send text/markdown. Claude Code happens to send text/plain. Same URL, different format, no client-side knowledge required.
In next.config.ts:
The regex looks scary but it's defensive. It matches text/markdown or text/plain only when those tokens appear before text/html in the Accept header. Browsers that happen to list text/markdown;q=0.5 after HTML still get HTML. Agents that ask for markdown first get markdown. Borrowed from vercel-labs/markdown-to-agents.
Markdown pair routes: we no longer recommend them
The first version of this post recommended giving every page a .md twin: /blog/some-post for browsers, /blog/some-post.md for agents. We shipped them on robotostudio.com. Both search engines have since told everyone to stop.
Google's official guidance, Optimizing your website for generative AI features on Google Search, is blunt: "You don't need to create new machine readable files, AI text files, markup, or Markdown to appear in generative AI search." The same guide tells you to reduce duplicate content because it wastes crawler resources. John Mueller went further on Bluesky, calling markdown pages for LLMs "such a stupid idea": why would a crawler want a page no user sees, when LLMs have parsed HTML since the beginning?
Bing's Fabrice Canel made the crawl budget case in one line: "really want to double crawl load? We'll crawl anyway to check similarity." That's the part that should worry you. Every .md twin is a second URL per page. Bing crawls it anyway to compare it against the canonical, so a 1,000-page site just became a 2,000-URL crawl for zero ranking benefit. X-Robots-Tag: noindex keeps the twins out of the index (we shipped that from day one) but it doesn't stop the crawler visiting them.
The good news: pair routes were always the redundant half of the pattern. Content negotiation on the canonical URL does the same job without minting new URLs. Googlebot asks for text/html and gets HTML; an agent asking for text/markdown gets markdown; one URL, no duplicates, no extra crawl. If you've already shipped .md twins, stop advertising them (sitemaps, Link headers, llms.txt) and let the Accept header carry the load.
Discovery via Link headers
The homepage advertises the agent-facing surfaces in an RFC 8288 Link header:
An agent crawling the homepage gets a structured map of where everything lives without parsing HTML.
What is llms.txt, and how to generate one
llms.txt is a plain markdown file at the root of your site that tells AI agents what's worth reading, in priority order. It's the convention proposed by Jeremy Howard: a single index an agent can fetch instead of crawling your navigation, listing both the HTML and markdown URLs for your best content. Think of it as a sitemap that talks.
A trimmed version of ours:
Don't hand-maintain this. A static llms.txt rots the moment you publish, so generate it from the same content layer that powers your pages. On the App Router that's a single static route handler, which is the whole "llms.txt generator" most sites actually need:
A loop over content you already have, regenerated on every build, nothing for an editor to keep in sync. We also publish llms-full.txt, the entire content of every page concatenated, for agents that want to embed the whole site once instead of re-fetching.
One caveat for balance: Google's generative AI guide lists llms.txt among the files you don't need, and that's accurate for Google's own AI features. The agents that read it are the non-Google ones: Anthropic's fetcher, Perplexity's crawler, and most coding agents. Ship it for them, not for AI Overviews.
The markdown actually has to be clean
This is the part that takes the actual time. If your content is MDX (markdown with React components inside), you can't just serve the file. Agents will choke on <InlineCTA> and <Newsletter> tags.
Our markdown-route.ts walks the MDX:
- Strips JSX components, keeping their text children
- Preserves fenced code blocks intact (delimiter-length-aware, so a 3-backtick example inside a 4-backtick fence survives)
- Preserves inline code spans (CommonMark equal-delimiter rule)
- Removes
import/exportstatements - Renders the frontmatter as a readable header (title, description, author, date)
Then it serves with:
The X-Robots-Tag matters. The /api/md/* destinations are real URLs anyone can fetch directly, and without the header Google can index them as duplicate copies competing with the canonical HTML pages.
How do I not go broke because of crawlers
Remember that GPTBot spike? Well of course, caching.
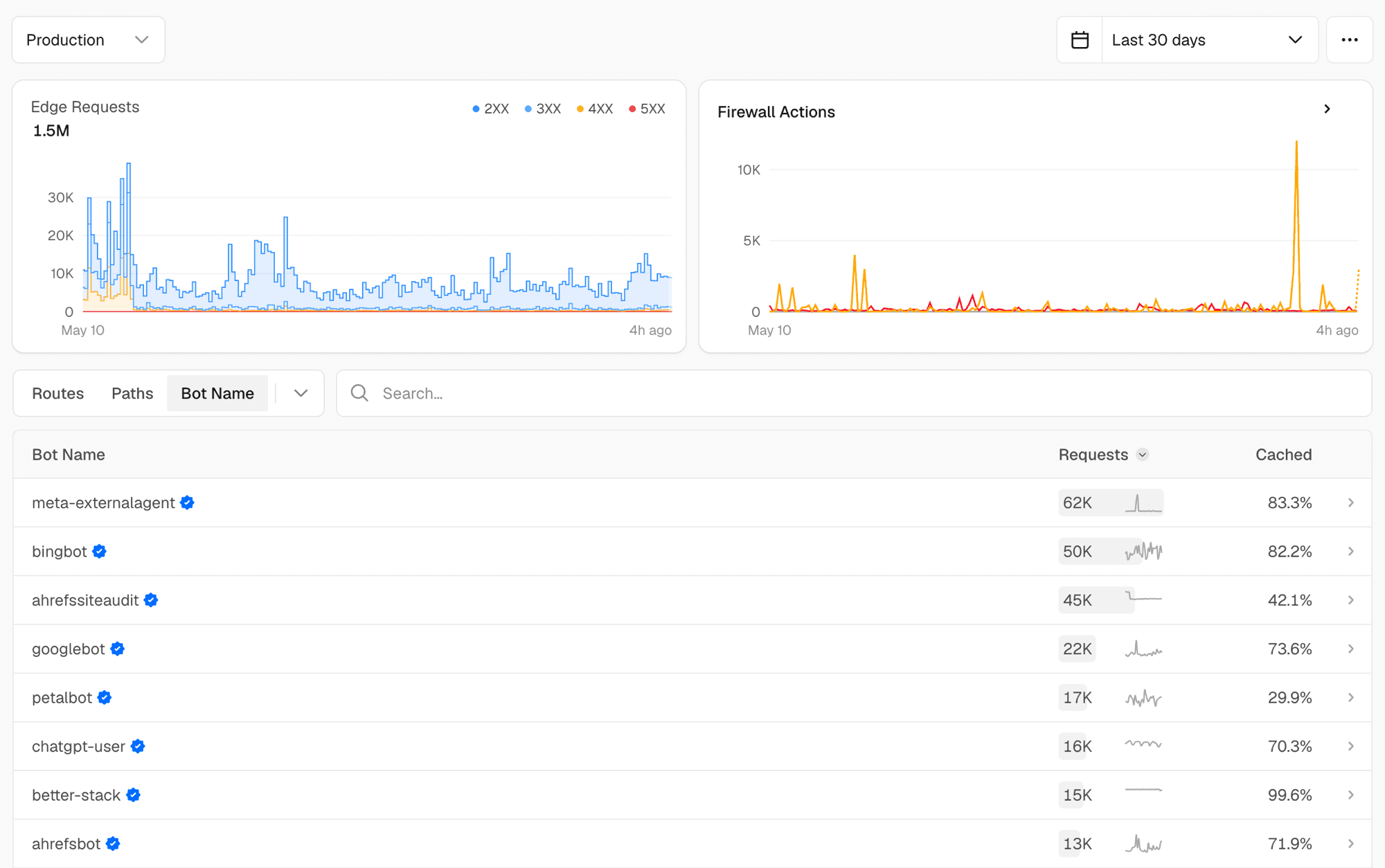
That's 30 days of bot traffic on robotostudio.com (well over 10% of our traffic). The reason we don't go broke is the column on the right. Notice how the meta crawler sits at 83% cached, bingbot at 82%, googlebot at 74%, chatgpt-user at 70%. That's due to aggressive caching.
Bots re-request the same URLs constantly, so when those hits land on the CDN instead of your rendering pipeline, a 10k spike costs roughly nothing.
The mechanics are boring on purpose. If a route can be static, make it static: a bot hitting a prerendered page is a CDN hit, not a function invocation. Content pages should be SSG or ISR, and the markdown route gets real Cache-Control headers (you've already seen ours ship s-maxage=86400 above). Reserve dynamic rendering for pages that genuinely need it, because that's the traffic crawler spikes can actually hurt.
The table lives in the Edge Requests tab of Vercel Observability, which breaks traffic down by individual bot and bot category, AI crawlers included. Or skip the clicking: open your project in the Vercel dashboard and throw /observability/edge-requests?period=30d&tab=botName on the end of the URL, and this exact page pops up. Look at it before assuming agent traffic is what's burning your budget: in our table the SEO audit tooling crawls harder than ChatGPT does.
The tools actually worth your time
You don't need a GEO tool suite. Most of this is verifiable with tools you already have, plus one category worth paying for.
Testing your own output
- Rich Results Test: paste a URL and confirm your JSON-LD parses and Google sees the schema types you wired up. A malformed property drops the whole block from rich results, and this is the fastest way to catch it.
- A terminal:
curl -H "Accept: text/markdown" https://yoursite.com/some-pageshows you exactly what an agent receives. If it comes back full of<div>s, your content negotiation isn't firing. - Your own
/llms.txtin a browser tab: confirm it loads and the links resolve. No product required.
Watching the crawlers
- Vercel Observability's Edge Requests tab (the bot table from earlier) is the cheapest way to see which AI crawlers hit you and how well you're caching them. Most paid "answer engine optimization tools" resell a worse version of this.
- Server logs if you're not on Vercel: grep for
GPTBot,ClaudeBot,PerplexityBot, andGoogle-Extended.
Monitoring citations
This is the category that earns its subscription, because you can't see it in your own analytics: whether AI engines actually mention you. Otterly, Peec, and ZipTie track share of voice across ChatGPT, Perplexity, Gemini, and Google AI Overviews, and the better ones for monitoring AI Overviews will tell you which of your pages got cited. Ahrefs and Semrush have bolted AI Overview tracking onto their keyword tools too, so if you already pay for one, check before buying another.
The honest order of operations: do the structural work first. A monitoring dashboard reading zero citations is an expensive way to find out you skipped the JSON-LD.
What to skip
A non-exhaustive list of things being sold as AEO (or GEO) that you can ignore:
.mdtwin URLs for every page. Google and Bing have both advised against separate markdown pages (see above). Content negotiation on the canonical URL covers the same agents without doubling your crawl footprint.- "AEO schema." There's no separate schema for AEO. Schema.org is the same standard SEO uses. Add
FAQPageif you have FAQs,HowTofor genuine how-tos,Articlefor posts. That's it. - AEO courses. The playbook is two paragraphs of HTTP and a sitemap. Don't pay for it.
- FAQ stuffing. Writing fake FAQs for the sake of FAQ schema is the new keyword stuffing. Google restricted FAQ rich results to authoritative government and health sites in 2023, so the rich-result payoff is gone for most sites anyway. Write FAQs because they're useful, not because they get cited.
- Worrying about which agent's leaderboard you're on. ChatGPT, Claude, Perplexity, and Gemini all use slightly different retrieval strategies. The signal that matters across all of them is the same one Google's used for fifteen years: do real people cite you?
Did it work?
It's been a few weeks. Two observations.
Crawler traffic is huge, referral traffic is small. The bots showed up immediately: 16K chatgpt-user requests in 30 days, the GPTBot spike from earlier, the whole observability table. Humans clicking through from AI answers are a different story, around 14 visits per month from Claude, Perplexity, and ChatGPT combined in our PostHog data. The sequence runs crawling first, citations second, clicks last, and we're at stage one. Doing this work now means you're ready for the slope when it arrives, and you get crawled cheaply in the meantime (see the caching section).
The work itself was small. A few rewrites in next.config.ts, a route handler, a markdown converter, and an llms.txt generator. If your site is on Next.js 16 it's an afternoon's work. If it's on something else, the same pattern works on any framework that supports header-conditional routing.
That's the whole playbook from someone who's actually done it, whichever acronym you file it under. Skip the courses.